from IPython.display import Image, display
from tqdm.notebook import tqdm
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
from sklearn.metrics.pairwise import cosine_distances
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib.ft2font as ft
import pandas as pd
import numpy as np
import osI’m currently in Beijing for a month studying Mandarin at a language school. Before coming to China I did a course at the Confucius Institute in the Netherlands. I passed the first HSK exam only a few months ago, so I’m definitely still a beginner.
What makes the Chinese language difficult are the tonal system and the logographic script. Unlike alphabets, hanzi requires memorizing thousands of unique symbols.
Currently I know a couple of hundred characters which I practice daily using flashcards. Some I’m able to memorize after seeing them once or twice, but there are quite a few that are trickier to remember.
I noticed that I often get confused when characters look very similar to each other. For example, the characters “矢” (shǐ, which means “dart”) and “失” (shī, which means “to lose”) look (and sound) pretty similar. The same is true for the characters “牛” (niú, which means “cow”) and “午” (wǔ, which means “noon”). There are many more characters like that.
I was looking for a way to practice discriminating between these visually similar characters. I realized I could use a pre-trained neural network to generate an embedding for each hanzi image. By calculating the cosine distance between these embeddings, I can mathematically quantify how similar two characters look.
In this post I’ll explain how I used this idea to create flashcards for the Anki system that focus specifically on these similar looking characters. Each flashcard shows the meaning in English and you’ll have to select its corresponding hanzi from a set of similar looking characters. If you want a hint you can get the pinyin of the character.
If you’re also studying Chinese you might find these useful. I’ll provide a link at the end to download the complete deck.
Including dependencies
We’ll start by downloading some dependencies. I’ll be using the VGG-16 pre-trained model to get the embeddings.
Creating images for common Chinese characters
I compiled a list of characters with their pinyin and meaning in English that you need to know for each of the HSK levels. This list contains each characters as a unicode character and we need to somehow convert these to images so we can extract the embeddings.
We’ll use a specific font file (Noto Sans CJK) that is placed in the working directory. This font has all the hanzi characters we need.
The following function uses matplotlib to turn a Chinese character into an image and saves it to disk.
FONT_FILE = 'NotoSansSC-Regular.ttf'
if not os.path.exists(FONT_FILE):
raise RuntimeError(
f"Font file '{FONT_FILE}' not found. Please place the Noto Sans CJK font file in the working directory."
)
FONT_PROPERTIES = fm.FontProperties(fname=FONT_FILE)
def save_hanzi_image(char='我', out_path='images/wo.png', img_size=(224, 224), fg='black', bg='white'):
"""Render a single Hanzi character to a square PNG using Matplotlib.
- char: Hanzi character to render
- out_path: output PNG path
- img_size: (width, height) in pixels
- fg/bg: foreground/background colors
Returns: out_path
"""
dpi = 100
width_in, height_in = img_size[0] / dpi, img_size[1] / dpi
fig = plt.figure(figsize=(width_in, height_in), dpi=dpi)
fig.subplots_adjust(0, 0, 1, 1)
ax = fig.add_axes([0, 0, 1, 1])
ax.set_axis_off()
fig.patch.set_facecolor(bg)
ax.set_facecolor(bg)
# Scale font to fit the square nicely
fontsize = int(min(img_size) * 0.77)
ax.text(0.5, 0.4, char, fontproperties=FONT_PROPERTIES, fontsize=fontsize,
ha='center', va='center', color=fg)
os.makedirs(os.path.dirname(out_path) or '.', exist_ok=True)
fig.savefig(out_path, dpi=dpi, facecolor=bg)
plt.close(fig)
return out_pathLet’s test the function by generating the image for the character “我”.
out_file = save_hanzi_image('我', out_path='images/我.png', img_size=(224, 224))
print(f"Saved 我 to {out_file} using {FONT_FILE}")
display(Image(filename=out_file))Saved 我 to images/我.png using NotoSansSC-Regular.ttf
Beautiful!
Note that we create images that are 224 by 224 pixels. This is the size that the VGG-16 pre-trained model expects.
Next we read the hanzi.csv file into a pandas dataframe. This is the file that contains the list of characters, their pinyin, meaning in English, and HSK level.
# Load hanzi list
df = pd.read_csv("hanzi.csv", sep=";", header=None, names=["pinyin", "hanzi", "meaning", "level"])Let’s look at 5 random rows to see what we got.
df.sample(5)| pinyin | hanzi | meaning | level | |
|---|---|---|---|---|
| 1497 | fán | 繁 | numerous | hsk5 |
| 58 | tā | 她 | she | hsk1 |
| 2368 | lǔ | 鲁 | rude | hsk7-9 |
| 1043 | cāo | 操 | to exercise | hsk4 |
| 839 | chí | 持 | to support | hsk3 |
There are quite a few characters that need to be converted.
df.shape[0]3229We loop through each character in this dataframe and convert them to a PNG image that is saved to disk.
chars = df["hanzi"].tolist()Rendering all characers will take a while but we only need to do this once.
# Render all characters
for ch in tqdm(chars, desc="Rendering characters"):
out_file = save_hanzi_image(ch, out_path=f"images/{ch}.png", img_size=(224, 224))Getting the embedding for each character image
I’ve used the term embedding a few times already, but what is that exactly?
An embedding in machine learning is a dense, lower-dimensional numerical vector representation of complex, high-dimensional data (such as words or images) that captures semantic meaning and relationships.
The way we get such an embedding is by using a pre-trained neural network. A popular choice for images is VGG-16.
VGG-16 is a 16-layer neural network trained on ImageNet to recognize 1000 different object categories. To get an embedding using this model we ‘cut off’ the final dense layers. This way, the model, instead of giving us a final prediction (like “Golden Retriever”), stops early at the last convolutional block, providing us with a raw numerical summary of the visual features it detected. This raw numerical summary is the embedding we’re interested in.
The following code initialized that VGG-16 model and calculates the embeddings. Because this is also a lengthy operation we save the result to a pandas dataframe.
# Build an embedding model from VGG16
# include_top=False removes the classification head
# pooling='avg' gives a single vector per image
embedding_model = VGG16(weights="imagenet", include_top=False, pooling="avg")
def image_to_embedding(image_path):
"""Load an image and return its VGG16 embedding vector."""
img = load_img(image_path, target_size=(224, 224))
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
embedding = embedding_model.predict(x, verbose=0)
return embedding[0]
labels = list(chars)
image_paths = [f"images/{ch}.png" for ch in chars]
# Compute embeddings
embeddings = np.vstack([
image_to_embedding(p) for p in tqdm(image_paths, desc="Calculating embeddings")
])
# Store embeddings in a DataFrame (as lists for easy saving)
df_embeddings = pd.DataFrame({
"hanzi": labels,
"embedding": embeddings.tolist()
})
# Save to disk
df_embeddings.to_csv("hanzi_embeddings.csv", index=False)Once saved, we can reload the embeddings.
# Read embeddings back from CSV
df_embeddings = pd.read_csv("hanzi_embeddings.csv")
# Convert embedding strings back to numpy arrays
df_embeddings["embedding"] = df_embeddings["embedding"].apply(eval).apply(np.array)Quantifying the similarity between characters
Now that we have the embedding for each character we can use the cosine distance to calculate how visually similar two characters are. The cosine distance varies from 0 to 2. When two embedding vectors point in roughly the same direction, in other words, the corresponding characters look similar, their cosine distance is close to 0. A cosine distance of 2 means the vectors point in opposite directions and are thus expected to be visually dissimilar.
Let’s get the embeddings and corresponding character from the dataframe we just loaded.
embeddings = df_embeddings["embedding"].tolist()
labels = df_embeddings["hanzi"].tolist()We can compute the pairwise cosine distances between all embeddings as follows.
cosine_dist = cosine_distances(embeddings)Finding visually similar characters
For each character we find the 9 most similar characters (excluding itself).
rows = []
for i in range(len(labels)):
# Get distances for this character
distances = cosine_dist[i]
# Get sorted indices (ascending order)
sorted_indices = np.argsort(distances)
# Skip index 0 (which is the character itself with distance 0) and take next 9
top_indices = sorted_indices[1:10]
# Build row
row = {'hanzi': labels[i]}
for j, idx in enumerate(top_indices, 1):
row[f'distractor_{j}'] = labels[idx]
row[f'distance_{j}'] = distances[idx]
rows.append(row)
# Create DataFrame
df_similar = pd.DataFrame(rows)By inspecting the first ten rows we see that our method seems to work pretty well.
df_similar.head(10).style| hanzi | distractor_1 | distance_1 | distractor_2 | distance_2 | distractor_3 | distance_3 | distractor_4 | distance_4 | distractor_5 | distance_5 | distractor_6 | distance_6 | distractor_7 | distance_7 | distractor_8 | distance_8 | distractor_9 | distance_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 一 | 二 | 0.045935 | 三 | 0.077222 | 兰 | 0.095345 | 亡 | 0.099232 | 工 | 0.101331 | 童 | 0.103229 | 上 | 0.104022 | 干 | 0.104424 | 曰 | 0.106709 |
| 1 | 不 | 才 | 0.056005 | 术 | 0.060588 | 否 | 0.065044 | 补 | 0.068950 | 查 | 0.069190 | 宋 | 0.073714 | 杯 | 0.074942 | 下 | 0.076708 | 尘 | 0.077286 |
| 2 | 了 | 子 | 0.058158 | 仔 | 0.079120 | 疗 | 0.089014 | 亨 | 0.097847 | 字 | 0.098124 | 丁 | 0.099952 | 刁 | 0.100861 | 尤 | 0.101229 | 才 | 0.101633 |
| 3 | 人 | 入 | 0.067497 | 介 | 0.092849 | 八 | 0.095127 | 从 | 0.111805 | 久 | 0.114532 | 大 | 0.128314 | 欠 | 0.128628 | 认 | 0.134102 | 众 | 0.135879 |
| 4 | 大 | 犬 | 0.009511 | 矢 | 0.032094 | 失 | 0.033000 | 太 | 0.034157 | 夫 | 0.038041 | 天 | 0.038582 | 庆 | 0.044371 | 关 | 0.047814 | 央 | 0.050737 |
| 5 | 出 | 山 | 0.026198 | 击 | 0.026936 | 世 | 0.032825 | 止 | 0.037128 | 吐 | 0.041082 | 叶 | 0.045467 | 臣 | 0.046879 | 岳 | 0.048023 | 正 | 0.048647 |
| 6 | 也 | 他 | 0.087145 | 地 | 0.096134 | 七 | 0.112868 | 匕 | 0.116716 | 把 | 0.117844 | 抱 | 0.118837 | 包 | 0.121424 | 孔 | 0.125540 | 扎 | 0.135460 |
| 7 | 子 | 字 | 0.035511 | 毕 | 0.037496 | 亨 | 0.041651 | 宁 | 0.042079 | 仔 | 0.046741 | 丁 | 0.047238 | 宇 | 0.047888 | 奇 | 0.051708 | 号 | 0.051845 |
| 8 | 用 | 明 | 0.048709 | 开 | 0.053404 | 届 | 0.058920 | 肝 | 0.060712 | 胆 | 0.062830 | 声 | 0.066363 | 再 | 0.066469 | 月 | 0.066484 | 阻 | 0.066581 |
| 9 | 行 | 何 | 0.039108 | 付 | 0.047234 | 订 | 0.048833 | 仔 | 0.049190 | 闭 | 0.051316 | 钉 | 0.052811 | 侍 | 0.054720 | 待 | 0.054922 | 讨 | 0.055550 |
Preparing the data for the Anki flashcards
Anki allows us to create a set of flashcards from a CSV file. We want each flashcard to show the pinyin, the meaning in English, and the options to choose from (the hanzi and its distractors). I also want the deck to have tags for each HSK level so I can limit my studies to the exam I’m working towards.
We can create the CSV we’ll feed into Anki as follows:
df_result = (df
.merge(df_similar, on='hanzi', how='left')
.drop(columns=[col for col in df_similar.columns if col.startswith('distance_')]))
df_result['level'] = df_result['level'].str.upper()
df_result = df_result[['hanzi', 'pinyin', 'meaning'] +
[f'distractor_{i}' for i in range(1, 10)] +
['level']]Let’s have a peek at what this file will look like.
df_result.head(10).style| hanzi | pinyin | meaning | distractor_1 | distractor_2 | distractor_3 | distractor_4 | distractor_5 | distractor_6 | distractor_7 | distractor_8 | distractor_9 | level | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 一 | yī | one | 二 | 三 | 兰 | 亡 | 工 | 童 | 上 | 干 | 曰 | HSK1 |
| 1 | 不 | bù | no | 才 | 术 | 否 | 补 | 查 | 宋 | 杯 | 下 | 尘 | HSK1 |
| 2 | 了 | le | did | 子 | 仔 | 疗 | 亨 | 字 | 丁 | 刁 | 尤 | 才 | HSK1 |
| 3 | 人 | rén | person | 入 | 介 | 八 | 从 | 久 | 大 | 欠 | 认 | 众 | HSK1 |
| 4 | 大 | dà | big | 犬 | 矢 | 失 | 太 | 夫 | 天 | 庆 | 关 | 央 | HSK1 |
| 5 | 出 | chū | to exit | 山 | 击 | 世 | 止 | 吐 | 叶 | 臣 | 岳 | 正 | HSK1 |
| 6 | 也 | yě | also | 他 | 地 | 七 | 匕 | 把 | 抱 | 包 | 孔 | 扎 | HSK1 |
| 7 | 子 | zǐ | child | 字 | 毕 | 亨 | 宁 | 仔 | 丁 | 宇 | 奇 | 号 | HSK1 |
| 8 | 用 | yòng | to utilize | 明 | 开 | 届 | 肝 | 胆 | 声 | 再 | 月 | 阻 | HSK1 |
| 9 | 行 | xíng | OK | 何 | 付 | 订 | 仔 | 闭 | 钉 | 侍 | 待 | 讨 | HSK1 |
It looks good so we’ll save it to disk.
df_result.to_csv("hanzi_confusion.csv", index=False)Creating a custom card design
I defined a custom card that shows the characters the user can choose from. By clicking pinyin the user will get to see the romanization of the word in Mandarin. After the user selects an option the card automatically flips. If the wrong option is selected, this is shown in red with the correct hanzi shown in green.

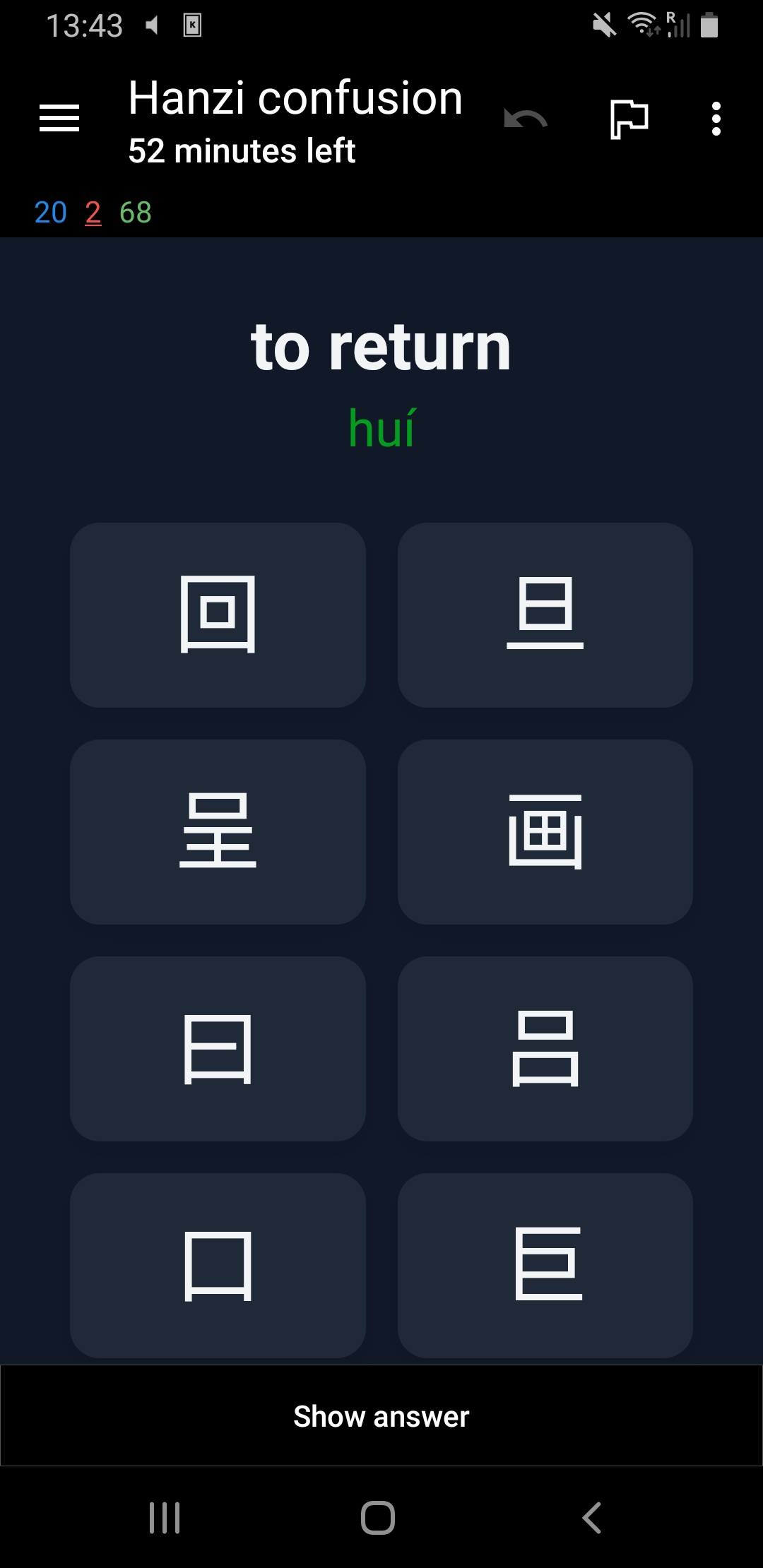
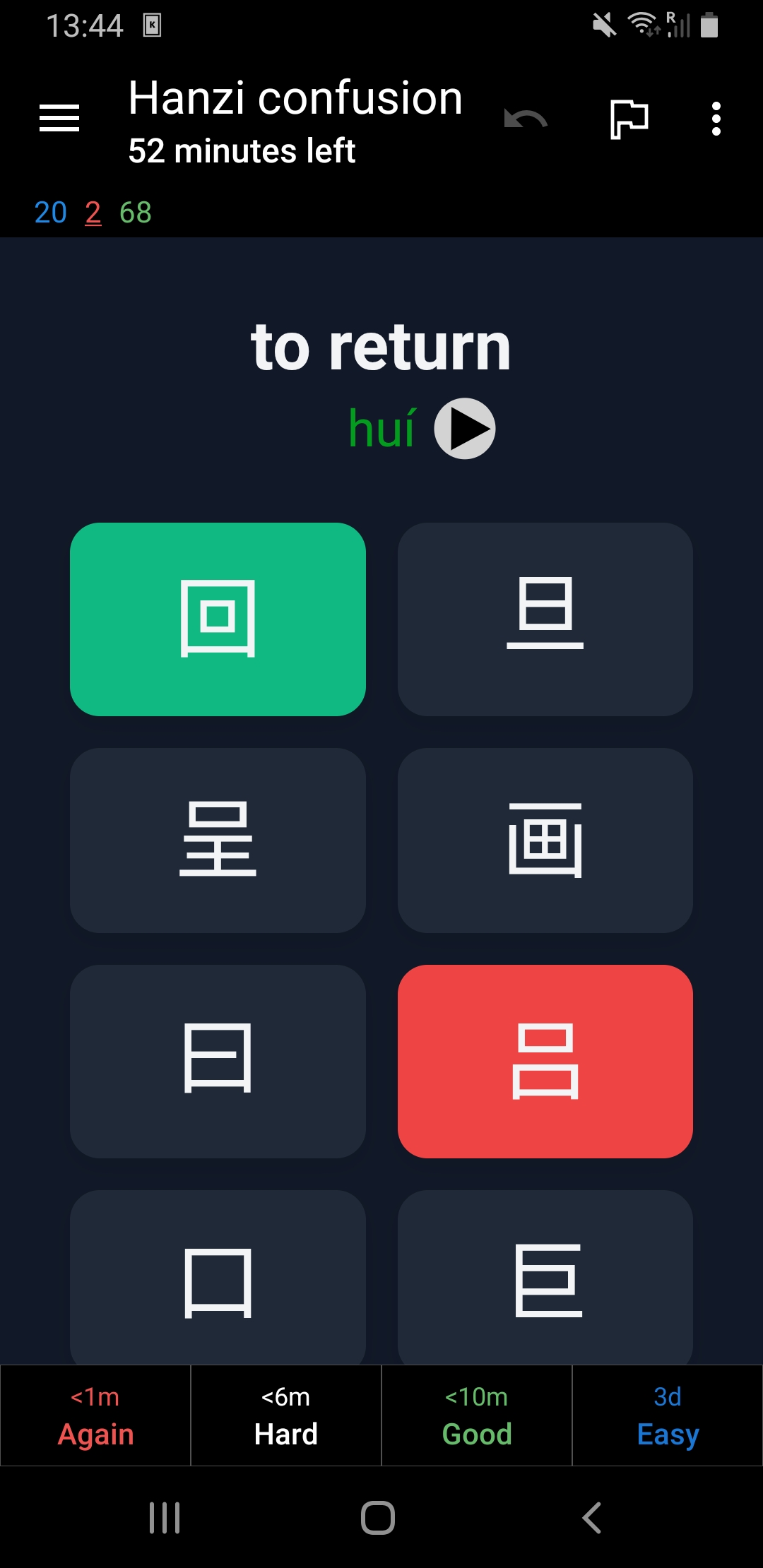
Both dark and light mode are supported.
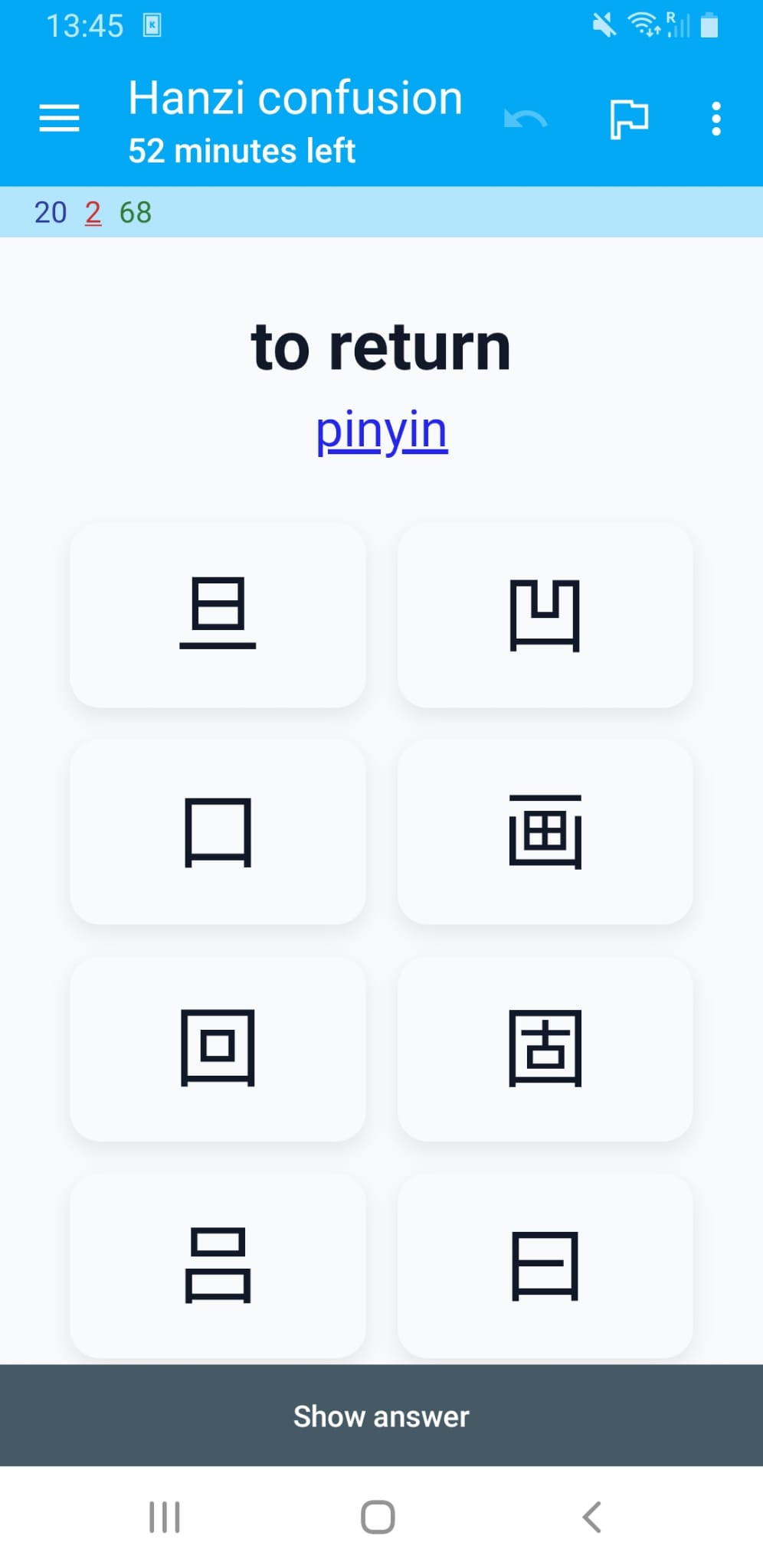
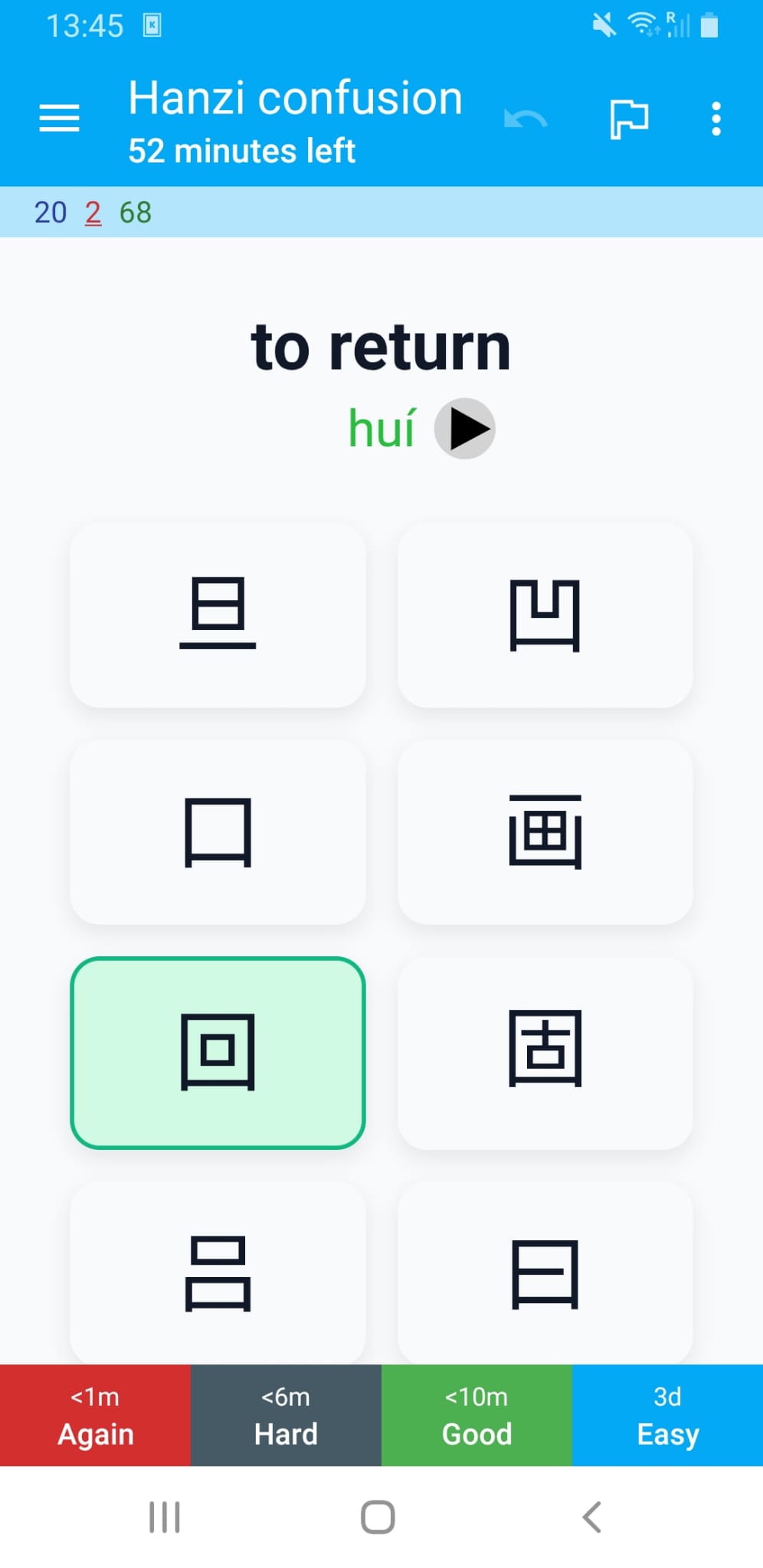
The card also supports landscape mode.
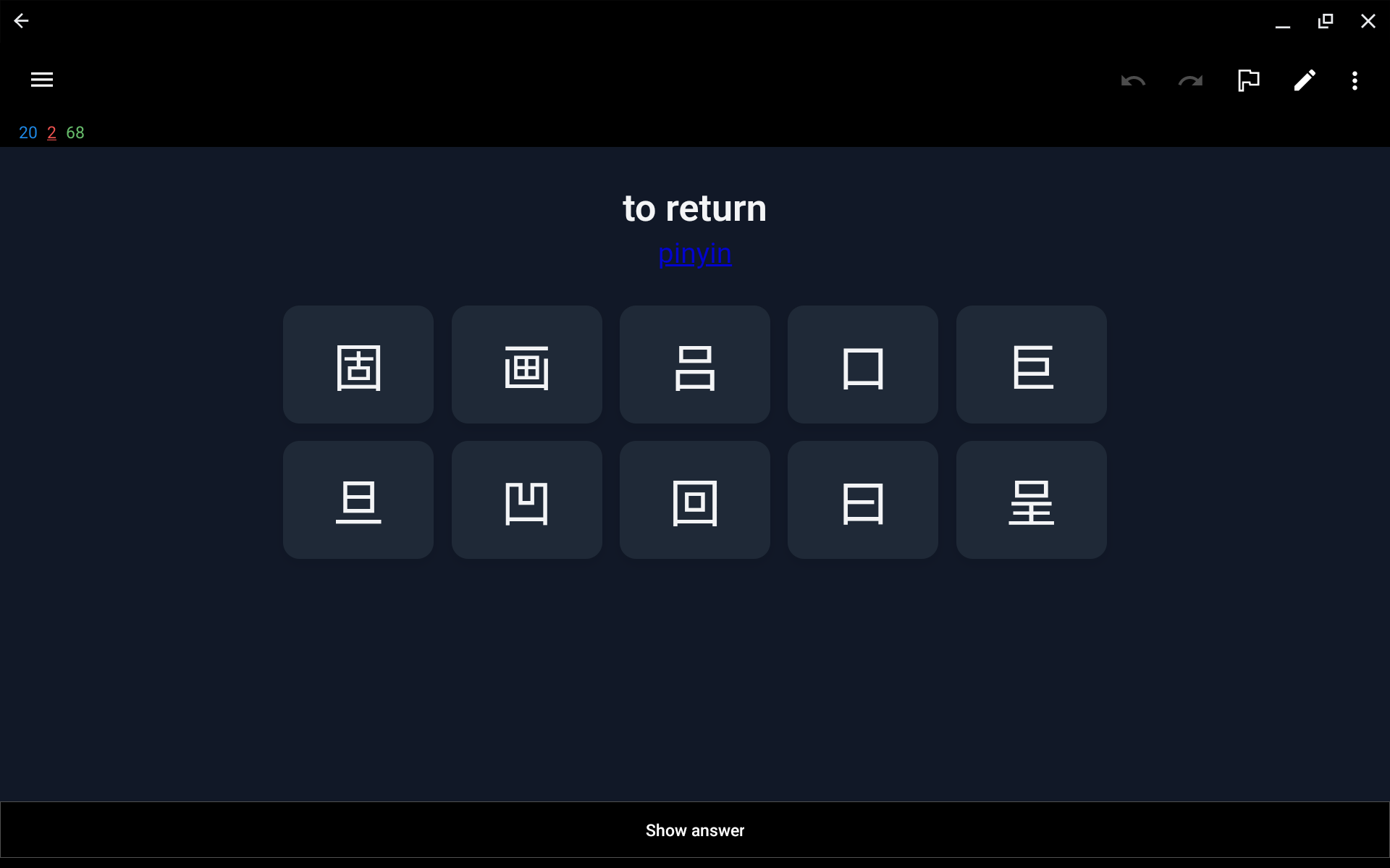
The pinyin is shown in red, green, blue, purple, or grey for first, second, third, fourth, or neutral tone respectively. I used the default colors from the popular Pleco app that many learners of Chinese use. On supported platforms you can make Anki pronounce the words using TTS.
The card has fields for each of the columns in the CSV file that we can now import into Anki.
Project links
You can find all files including the custom card in this GitHub repository:
![]()
The complete deck can also be downloaded from AnkiWeb.
I hope this helps in your Chinese studies.
加油!